1. From human memory to activation diffusion network
Memory is a fundamental cognitive process that allows the brain to store, acquire, and recall information. It serves as a temporary storage system when sensory cues disappear (Benjamin 2007). Memory plays a crucial role in encoding, storing, retaining, and recalling everything from simple sensory data to complex knowledge and experiences. Additionally, memory is the basis for learning, planning, and decision-making (Benjamin 2007; Nussenbaum, Prentis, and Hartley 2020). Specifically, it enables us to learn from past experiences and simulate potential future outcomes, thereby influencing current behavior and future actions (Schacter et al. 2012).
The formation of memories, their recall, and reasoning based on them involve a combination of systems and physiological processes that allow humans to adapt well to their environment (Schacter et al. 2012; Camina and Güell 2017; Nairne and Pandeirada 2016).Memory formation comprises three stages: information perception, encoding, and storage (Atkinson and Shiffrin 1968). These stages correspond to three types of memory: (1) sensory memory (Atkinson and Shiffrin 1968) briefly stores raw physical stimuli from primary receptors such as vision and hearing; (2) short-term memory (STM) (Baddeley 2000) involves the transient storage and manipulation of information, allowing individuals to temporarily memorize small amounts of data to perform current and future tasks; (3) long-term memory (LTM) (Camina and Güell 2017) is the long-term storage of information, divided into episodic and implicit memory. Episodic memory consists of knowledge processed and recalled at a conscious level, such as personal experiences and specialized knowledge, while implicit memory encompasses skills and habits expressed without conscious awareness, such as fear, riding a bicycle, heart rate regulation, and other conditioned reflexes (Smith and Grossman 2008). In contrast to the limited-capacity sensory memory and STM, LTM is a more complex cognitive system with an unlimited capacity for long-term storage and retrieval of a wide range of information, including factual knowledge and personal experiences.
Memory can also be categorized into contextual memory, referring to an individual’s personal experiences, and semantic memory, referring to textual knowledge about concepts (Renoult et al. 2019). Storing contextual and semantic knowledge allows individuals to construct new knowledge based on past experiences, facilitating their survival (Kazanas and Altarriba 2015). In addition to storing information and memories, LTM plays an important role in learning and reasoning. It can automatically relate relationships and attributes between objects (Nairne and Pandeirada 2016), giving individuals the ability to use stored skills and concepts to make rational decisions by evaluating different choices in various environments and predicting possible outcomes (Camina and Güell 2017).
The formation and consolidation of LTM involve several brain regions, including the prefrontal lobe, associated with working memory and situational memory in LTM (Blumenfeld and Ranganath 2019), and the temporal lobe, associated with semantic memory in LTM (Simmons and Martin 2009). The hippocampus acts as a relay station for information (Squire and Zola-Morgan 1991) and can integrate situational memory into the semantic memory knowledge network stored in LTM (Renoult et al. 2019). Consequently, even for the same concept or knowledge, the knowledge network formed by different individuals can vary.
Each individual has unique experiences and backgrounds, leading to different understandings and reactions when interpreting the same information. LTM is stored as a vast and complex semantic network, which includes various types of interconnected nodes, such as concepts, memories, and experiences (Collins and Loftus 1975). Other kinds of memories or experiences are also integrated into this network; for example, an individual’s representation of abstract concepts (e.g., time) may be based on physical sensations (Casasanto and Boroditsky 2008). In such cases, individuals associate time with their experiences, forming their knowledge network. This form of organization is named semantic networks or knowledge networks, emphasizing how information is interconnected and organized according to meaning (Lehmann 1992).
In this article, we use the term semantic network to represent the form of memory storage and organization in LTM, while knowledge network refers to an artificially built knowledge network. In a semantic network, concepts are represented as nodes, and concept-to-concept relationships are represented as edges between nodes, with edge weights indicating the strength of the association. A higher edge weight implies a closer relationship between two nodes, typically resulting in a higher recall rate after receiving a stimulus (Anderson 1983). Learning and memorizing new knowledge and experiences involve building new edges or reinforcing existing ones. This organization facilitates information retrieval by enabling individuals to jump from one concept to another in the network and simultaneously activate neighboring nodes to form knowledge connections, even if there is no direct correlation between them (Lehmann 1992). An interesting example is that in the semantic network of some police officers, black people produce a strong association with weapons, and this association is even stronger if the police officer is sleep-deprived (James 2018). Another example is that an individual’s preference for Coca-Cola or McDonald’s is determined by their attitude and reflected in their semantic network (Lee and Kim 2013; Karpinski, Steinman, and Hilton 2005).
Homogeneous networks consist of nodes with similar properties or characteristics (Mhatre and Rosenberg 2004). Nodes represented as the same kind of elements and edges connected nodes with high correlations, which jointly creating a homogeneous network. The two examples mentioned above illustrate that different individuals form different LTMs, and the memory contents stored in their LTMs do not satisfy homogeneity.
Moving from one concept to an unrelated concept is impossible in a homogeneous network. The process by which individuals store their memories in the same semantic network and retrieve information from LTM is often described as spreading activation, and this network is also called the spreading activation network (Sharifian and Samani 1997). In this network model, if an initial node is activated, this activation state spreads to other nodes along connected edges. This diffusion process can quickly span multiple network layers, extensively activating the concepts and memories associated with the initial node. When a node receives activation above a certain threshold, it is fully activated like neurons. Otherwise, it will not be activated. This may lead to the recall of specific memories, the formation of decisions, or the generation of problem-solving strategies.
As mentioned earlier, some unrelated concepts in a semantic network may have relatively strong associations. The implicit association test (IAT) paradigm proposed by Greenwald can effectively test the edge connections between nodes of an individual in a semantic network (Greenwald, McGhee, and Schwartz 1998; Greenwald et al. 2009). This paradigm tests the strength of association in the human brain between two nodes, i.e., the edge weights. The mechanisms of association and activation in activation diffusion networks depend on the strength of association between nodes. If the strength is high, the probability of activation is relatively high; if the strength is low, there is a higher probability of non-activation. This theory partly explains the forgetting phenomenon that occurs in human memory. Additionally, activation diffusion networks enable individuals to retrieve necessary information, reorganize their memories, and apply knowledge to the same or different situations. In summary, activation diffusion networks effectively account for the dynamic nature of memory retrieval and use.
2. Unique advantages of human cognitive abilities
Compared to computer programs, humans possess an ability to think about problems from different perspectives and exhibit greater flexibility in knowledge association (Lehmann 1992). Therefore, humans have the advantage of applying knowledge from one domain to another seemingly unrelated domain. For example, concepts from biology can be transferred to economics (Lawlor et al. 2008), economic models to the field of electronic information (Han et al. 2019), and linguistic concepts to neuroscience (Mayberry et al. 2018) and computer science (H. Zhang et al. 2023). This characteristic has led humans to create many cross-disciplinary fields, such as artificial intelligence, computational biology, neuropolitics, and bioinformatics. Humans can use intuition and creative thinking to solve problems, and this ability to think across domains allows them to make new connections between different areas, thereby building new disciplinary knowledge.
The human brain contains approximately 100 billion neurons and roughly the same number of glial cells (Bartheld, Bahney, and Herculano-Houzel 2016), of each connected to thousands of others via synapses (Herculano-Houzel 2009). Neurons and glial cells form extremely complex networks. Neurons communicate via the all-or-none principle (Pareti 2007), and glial cells play crucial roles in central nervous system formation, neuronal differentiation, synapse formation (Allen and Lyons 2018), regulation of neuroinflammatory immunity (Yang and Zhou 2019), and neurological diseases like dementia (Kim, Choi, and Yoon 2020), in addition to their traditional supportive functions (Wolosker et al. 2008). Such complexity lays the foundation for an individual’s ability to process information, experience emotions, maintain awareness, and exhibit creativity.
Drawing on the fundamentals of human cognition, artificial neural networks have been simulated using computers to mimic the brain’s information processing. They emulate human cognitive abilities to some extent, excelling in tasks like learning, decision-making, and pattern recognition that humans are naturally proficient at (Agatonovic-Kustrin and Beresford 2000; Parisi 1997). The simulation of human cognitive abilities has shown great potential (Parisi 1997; Zahedi 1991). However, the neurons used in deep learning and artificial neural networks are highly abstract, and the architecture is unable to account for the neurons (Cichy and Kaiser 2019). Therefore, this field has focused more attention on fitting data rather than interpreting it (Pichler and Hartig 2023).
Currently, the field of deep learning is more concerned with fitting data, the effect of fitting is used as a guiding criterion in this field, rather than integrating cognitive mechanisms discovered by neuroscience (Chavlis and Poirazi 2021). Much of the progress in deep learning over recent decades can be attributed to the application of backpropagation, often used with optimization methods to update weights and minimize the loss function. However, while neural networks and deep learning are biologically inspired approaches, the biological rationality of backpropagation remains questionable, as activated neurons do not acquire features through backpropagation (Whittington and Bogacz 2019; Lillicrap et al. 2020; Aru, Suzuki, and Larkum 2020). Currently, two mainstream learning mechanisms have been identified in the human brain using electrophysiological methods: Hebbian learning (Munakata and Pfaffly 2004) and reinforcement learning (Botvinick et al. 2019). Additionally, synaptic pruning may be related to learning (Halassa and Haydon 2010), and epigenetic mechanisms also play an important role (Changeux, Courrège, and Danchin 1973). Although Hebbian learning, reinforcement learning, and attempts to migrate human cognitive mechanisms have been applied in deep learning for years, they still cannot perfectly reproduce human learning features (Volzhenin, Changeux, and Dumas 2022). Comparatively, the energy consumption when using neural networks for reasoning is huge (Desislavov, Martínez-Plumed, and Hernández-Orallo 2023), in contrast to the human brain’s lower energy usage for training and reasoning (Attwell and Laughlin 2001).
Another example is the attention mechanism in neural networks, inspired by human attention (Vaswani et al. 2023). Attention is a cognitive ability that selectively receives information with limited resources (Nelson Cowan et al. 2005). It’s a complex biological process involving multiple brain regions, encompassing not only selective attention but also coordinated consciousness, memory, and cognition. Selective attention mechanisms are associated with short-term memory, where only 3-5 chunks of original stimuli can enter during a single session (N. Cowan 2001), with attention lasting just a few seconds to minutes (Polti, Martin, and Van Wassenhove 2018). This selective mechanism allows humans to focus on targets with limited resources, reducing cognitive resource consumption (Buschman and Kastner 2015), refining elements deposited into memory (Chun and Turk-Browne 2007), delimiting the problem space, and narrowing memory retrieval in problem-solving situations (Wiley and Jarosz 2012). Human intuition about numbers may also relate to attention (Kutter et al. 2023). Thus, selective attention is crucial for cognitive activities like perception, memory, and decision-making.
Attention mechanisms in deep learning, inspired by human selective attention, which have been successfully integrated into various frameworks (Niu, Zhong, and Yu 2021), greatly improving performance in tasks like natural language processing (NLP), computer vision, and speech recognition (B. Zhang, Xiong, and Su 2020; Guo et al. 2022; Ding et al. 2021). In recent years, the Transformer model, relying on self-attention mechanisms to process data, has demonstrated superior performance across various tasks (Vaswani et al. 2023; Khan et al. 2022). Its multi-head attention mechanism performs multiple parallel self-attention computations with different parameters, allowing the model to capture information from different subspaces and improving fitting efficiency and accuracy (Liu, Liu, and Han 2021). Practically, with the Transformer, neural networks have made significant progress in areas like NLP and vision tasks.
Attention mechanisms in deep learning are implemented through mathematical functions that assign weights to different elements of the input data (Niu, Zhong, and Yu 2021; De Santana Correia and Colombini 2022). However, a subset of studies has found that the attention mechanism in deep learning cannot fully simulate human attention and lacks the cognitive and emotional context that human attention encompasses (Lai et al. 2021). Despite these differences, artificial neural networks have been successfully applied in several fields, including image and speech recognition, natural language processing, robot control, gaming, and decision support systems. These applications demonstrate the power of artificial neural networks in dealing with complex problems and simulating certain human cognitive processes while highlighting the unique advantages of models that simulate human cognitive abilities.
3. Simulating Human Cognitive Abilities: The Way Forward
In recent years, the Transformer model has excelled in various tasks that rely on self-attentive mechanisms for data processing (Vaswani et al. 2023; Khan et al. 2022). It departs from traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs), favoring a comprehensive utilization of attentional mechanisms to process sequential data. The Transformer’s attention model is primarily applied through self-attention and multi-head attention mechanisms. The self-attention mechanism considers all other elements in the sequence when processing each input element, enabling the model to capture long-range dependencies within the sequence (Vig and Belinkov 2019). Each element is transformed into query (q), key (k), and value (v) vectors, representing the current lexical element, other lexical elements, and the information contained in the lexical element, respectively. The attention score is computed by calculating the similarity scores of q and k, and weighted summing over v. Recently, LLMs have employed the Transformer’s framework, demonstrating an improved simulation of human cognition.
LLMs are large-scale simulations of human cognitive functions (Binz and Schulz 2023), and their emergence mark a significant advancement in computers’ ability to simulate human cognition. LLMs possess enhanced reasoning capabilities, and Claude 3, released this month by Anthropic, exhibits self-awareness through contextual understanding in a needle-in-a-haystack task (Anthropic 2024; Kuratov et al. 2024). In zero-shot problem scenarios, LLMs’ reasoning abilities without prior knowledge surpass those of humans, who rely on analogies for reasoning (Webb, Holyoak, and Lu 2023). Furthermore, LLMs can comprehend others’ beliefs, goals, and mental states with an accuracy of up to 80%. Notably, GPT-4, considered the most advanced LLM, can achieve 100% accuracy in theory of mind (ToM) tasks after suitable prompting, indicating a human-like level of ToM (Thaler 1988).
LLMs can also simulate human behavior observed in experiments, such as the ultimatum game (Thaler 1988), garden-path sentences (Ferreira, Christianson, and Hollingworth 2001), loss aversion (Kimball 1993), and reactions to the Milgram electric shock experiment (Blass 1999; Aher, Arriaga, and Kalai 2022). Additionally, LLMs exhibit cognitive biases or errors that humans typically demonstrate, such as additive bias (Winter et al. 2023), where individuals default to adding or modifying existing content rather than deleting or pushing back when problem-solving (Adams et al. 2021). LLMs produce various human cognitive effects, including priming effects and biases (Koo et al. 2023; Shaki, Kraus, and Wooldridge 2023), suggesting that LLMs mimicking human cognitive processes may possess cognitive abilities approaching the human level.
In specific domains, LLMs closely mimic human-specific abilities. For instance, ChatGPT’s accuracy in medical diagnosis and providing feasible medical advice in complex situations is comparable to that of human physicians (Hopkins et al. 2023). The performance metrics show that it diagnoses up to 93.3% of common clinical cases correctly (Hirosawa et al. 2023). Furthermore, in standardized clinical decision-making tasks, ChatGPT achieves an accuracy rate close to 70% (Rao et al. 2023), similar to the expected level of third-year medical students in the United States (Gilson et al. 2023). Due to GPT-4’s superior ToM, it correctly answered 90% of soft skill questions (Brin et al. 2023), demonstrating excellent clinical skills.
However, ChatGPT’s ability to handle complex questions remains unsatisfactory compared to widely used technologies like Google search (Hopkins et al. 2023). It cannot fully replicate professional clinicians’ decision-making abilities when faced with complex problems, primarily due to its text-based training data, resulting in less satisfactory performance in non-text-based tasks (Y. Zhang et al. 2024). Furthermore, in patient care and other medically related domains, it sometimes generates false or misleading information, potentially causing doctors, nurses, or caregivers to make erroneous decisions, endangering patients’ lives (Z. Ji et al. 2023).
LLMs often contain billions to hundreds of billions of parameters, making it difficult to implement debugging and understand their decision-making processes (Z. Ji et al. 2023; Khullar, Wang, and Wang 2024). Therefore, developing relatively interpretable models is a viable alternative at the moment. These models are trained in specific areas of expertise, possessing prior knowledge and learning not exclusively from samples. Recently, the life2vec model successfully predicted the relationship between early mortality and aspects of an individual’s personality traits, demonstrating relatively good predictive efficacy (Savcisens et al. 2023). The model provides clinicians and family physicians with insights and assistance that can help patients better manage their lifespan, showcasing the potential of specialized models.
4. Simulating human knowledge representation using large-scale medical knowledge networks
In summary, we have found that computer models simulating human cognitive abilities tend to achieve very good model fitting results, such as Transformer-based neural network models like LLMs. While LLMs perform satisfactorily in a wide range of contexts, there are multiple aspects that have not been addressed adequately in addition to the aforementioned medical issues.
LLMs require an enormous number of parameters and a vast amount of training data, consuming substantial computational resources during the training process (S. Zhang et al. 2022). Even after training, reasoning with LLMs consumes significant computational resources (Samsi et al. 2023). Furthermore, LLMs produce a large carbon footprint (S. Zhang et al. 2022; Faiz et al. 2023) and require considerable water consumption for cooling (George, A.S.Hovan George, and A.S.Gabrio Martin 2023), exacerbating environmental concerns and extreme climate events. As computational power is concentrated in a few labs, LLM also exacerbates inequality issues and prevents most labs from gaining LLMs (S. Zhang et al. 2022).
LLMs are often considered black boxes, making it difficult to understand and explain their operating mechanisms. Recently, OpenAI has demonstrated early forms of artificial intelligence in LLMs by increasing their parameters and training sample size (OpenAI et al. 2023; Bubeck et al. 2023; Schaeffer, Miranda, and Koyejo 2023; Wei et al. 2022), challenging many scholars’ perceptions. Some have argued that it resembles the Chinese room problem, where LLMs do not emerge intelligence but rather acquire deeper features of language, as consciousness may be a special form of language (Hamid 2023). Others contend that the emergent intelligence of LLMs is merely wishful thinking by researchers (Schaeffer, Miranda, and Koyejo 2023). Alternatively, it has been proposed that LLMs resemble human societies, where a large number of individuals collectively exhibit abilities that individuals do not possess, with emergent capabilities resulting from complex relationships between numerous data points, akin to ant colony algorithms.
We suspect the possible reasons for their emergence regarding the capabilities demonstrated by LLMs. As noted earlier, developing relatively interpretable specialized models would maximize usability and transparency, making them safer for clinical applications. Over the past decades, humans have accumulated substantial historical experience in fighting diseases and a large number of low-practice-value papers and monographs (Hanson et al. 2023). Translating this experience into clinical resources in bulk has become an important issue in modern medical research.
We observed that clinicians tend to treat patients automatically based on their diseases while considering comorbidities the patients may have, e.g., heart disease, high cholesterol, and bacterial infections. We aimed to develop a model that could simulate this ability while maintaining model interpretability. Therefore, we adapted the original spreading activation model by replacing the LTM with a knowledge network and substituting the memory search and inference with a random walk approach to simulate human abilities.
LLMs are often trained using knowledge from publications, and the promising life2vec model uses medical information from Danish citizens. Here, we use medical texts to build knowledge networks to train our models. A knowledge network is a large-scale, graph-structured database that abstracts core concepts and relationships in reality, allowing AI systems to understand complex relationships and reason about them. It can integrate various data sources and types to represent relationships between elements and their properties. Knowledge networks abstract the real world for AI systems (Martin and Baggio 2020), enabling them to solve complex tasks and reason about the world (S. Ji et al. 2022).
Biomedical knowledge is characterized using formalism, an abstraction process of the human brain to model systems formally and mathematically (Phillips 2020). Although biomedical knowledge does not use formulas to describe biological processes like mathematics, physics, and chemistry, knowledge networks can establish the mechanisms involved in biological processes (Martin and Baggio 2020). For example, biologists usually use nodes to represent genes and edges to represent regulatory relationships between genes.
Once the knowledge network is having constructed, we can simulate how humans utilize LTM by choosing the random walk approach. Numerous studies have shown that random walk can effectively simulate human semantic cognition (S. Ji et al. 2022; Kumar, Steyvers, and Balota 2021) and is consistent with the human memory retrieval process. Compared to the outputs of spreading activation, that of computer-simulated random walks showed higher correlation with the spreading activation model’s results (Abbott, Austerweil, and Griffiths 2015; Zemla and Austerweil 2018; Siew 2019). Furthermore, brain scientists have used random walk algorithms to explore theoretical concepts (Abbott, Austerweil, and Griffiths 2015; Siew 2019) or simulate specific human cognitive behaviors to reduce experimental errors introduced by external environments (Abbott, Austerweil, and Griffiths 2015; Zemla and Austerweil 2018).
Similar to the repeated, random selection of various possible solutions in the human brain, the random walk simulates the random events that exists in individual problem-solving and decision-making processes. As a diffusion model, it is applicable to a wide range of situations, even computer-simulated human societies (Park et al. 2023), demonstrating the broad applicability of such computer models to many different biological scenarios.
5. Conclusion
Humans excel at employing existing problem-solving strategies (Kaula 1995). With the rapid advancement of computer technology, there has been a surge in research articles on drug repositioning aided by computational biology and bioinformatics. Figure demonstrates that the relative number of articles on drug repositioning included in PubMed, shows an increasing trend over the years with a more significant rise in recent years. The calculation method also exhibits the same increasing trend. The banana metric has proven effective in quantifying and analyzing research interest trends across various fields, which is defined as the number of articles retrieved using banana as a keyword per year (Dalmaijer et al. 2021).
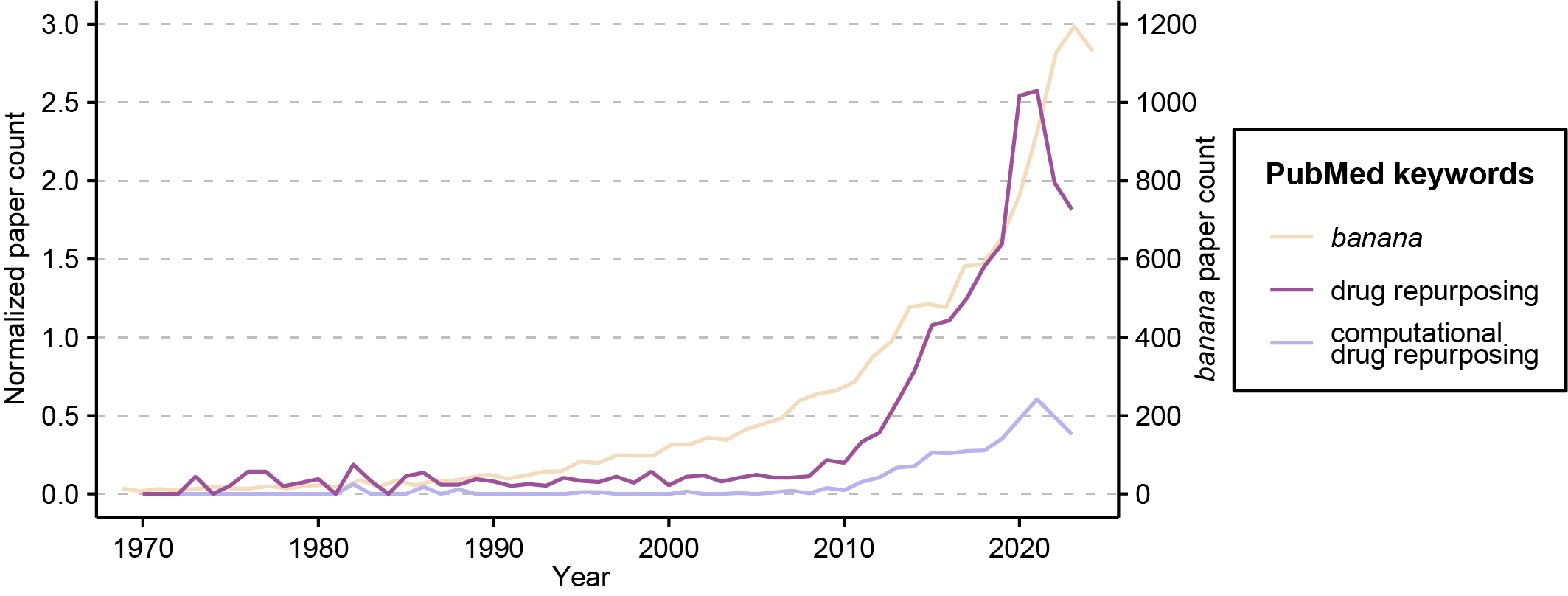
Bibliometric analysis for drug repurposing. Drug repurposing gains significant attention since 2010. We adopted banana scale to depict this trend.
We observed that clinicians tend to treat patients symptomatically based on their diseases while considering other comorbidities the patients may have, for example, heart disease, hyperlipidemia, and bacterial infections. We aimed to develop a model that could simulate this ability while maintaining interpretability. Therefore, we adapted the original spreading activation theory by replacing the LTM with a knowledge network and substituting the memory search and inference with a random walk approach to simulate human abilities.